



ウィペットの呼び戻しって、ぶっちゃけ可能なの?
なんでうちの子、呼んでも「シカト」するんだろう?
爆走モードに入った時、脳内では何が起きてる?
「サイトハウンドは呼び戻せない」って噂の真相は?
結局、何から練習し始めればいいの?
家の中で今すぐできる、一番簡単な練習って?
こんな疑問・悩みを解決します。
1.ウィペットの呼び戻しは可能なのか?
2.なぜ逃げる?本能と脳のメカニズム
3.成功率を劇的に上げる「3つの原則」
4.本能をハックする「ご褒美」戦略
5.競技者流!興奮した愛犬の回収術
6.命を守るためのNG行動と緊急対策
※本記事は動物行動学・神経科学の研究(文献一覧は末尾に記載)、およびルアーコーシング競技の最前線での一次情報をもとに執筆しています。
ウィペットの呼び戻し(リコール)は可能です。ただし、サイトハウンド特有の追跡本能を正しく理解した上で、高価値な報酬トレーニングと逃走防止のための環境管理を組み合わせることが、成功の絶対条件になります。
この記事では、サイトハウンド特有の逃走事故が起きる理由から、絶対にやってはいけないNG行動、ルアーコーシング競技者が実践する極度の興奮状態からの回収テクニックまでを、実体験と科学的エビデンスをもとに詳しく解説します。ウィペットの命を守るために最も重要なスキルが「確実なリコール」です。
- ウィペットが逃走する3つの理由と脳内メカニズム
- 呼び戻し成功率を上げる3つの原則と階層化トレーニング
- ドッグランで捕まえられない問題の解決方法(実体験)
- ルアーコーシング後の確実な回収ルーティンと食事管理
1. ウィペットの呼び戻し(リコール)は可能?できないと言われる理由と真実
結論から言えば、ウィペットの呼び戻しは十分に習得できます。 ただし、他の犬種と同じ方法ではなく、「動くものを目で追う本能」を前提とした専用の訓練が必要です。また、どんなに訓練しても「100%の保証」は不可能なため、命を守る環境管理が常にセットになります。
サイトハウンドは「呼び戻し不能」と言われる理由
ウィペットをはじめとするサイトハウンド(視覚猟犬)は、はるか遠くで動く獲物を自らの「目」で発見し、その圧倒的なスピードで追いかけて捕らえるよう、何百年にもわたって選択交配されてきた歴史があります。
解剖学的に見ても、ウィペットなどの長頭種(dolichocephalic)の眼球には「ビジュアル・ストリーク(Visual streak:視覚帯)」と呼ばれる、網膜の神経節細胞が横帯状に高密度に集まった領域が発達する傾向があり、優れた広視野を持つとされています(McGreevy et al., 2004)。Visual streakとは、網膜上で水平帯状に神経節細胞が集中する構造で、地平線方向の動きを広い範囲で検出する能力に関係するとされています。これにより、地平線を横切るわずかな動きを超広角で捉えやすい構造を持っています。
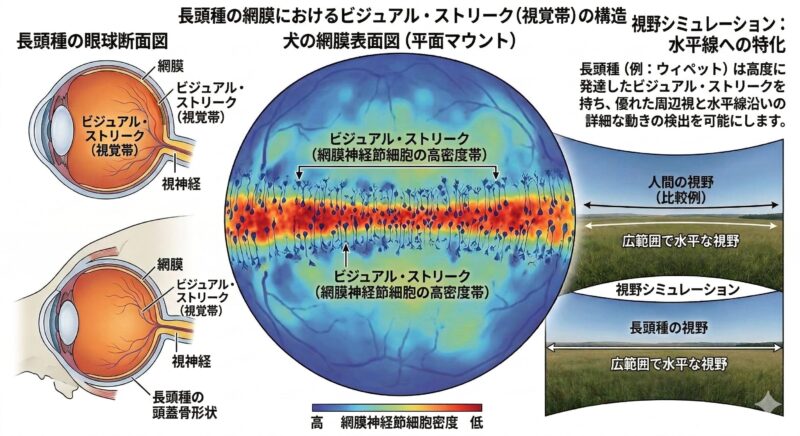
そのため、「飼い主の指示(聴覚情報)を聞いてから動く」牧羊犬や「匂い(嗅覚情報)を頼りに探索する」ハウンド犬などとは異なり、「自分の視覚で獲物を捉え、自らの判断で瞬時にトップスピードに乗る」ように神経回路が設計されています。視覚刺激への反応が非常に強く、結果として音声指示(飼い主の声)への反応が低下する場合があります。これが「サイトハウンドは呼び戻しができない」と誤解される最大の理由です。
結論:訓練すれば可能だが条件がある
本能の強さを科学的に理解した上で、それを上回る「飼い主の元へ戻るメリット(強力な正の強化)」を犬の脳に学習させれば、リコールは確実に機能するようになります。重要なのは、犬に「指示に従わせる(罰の回避)」のではなく、「飼い主のところへ行くのが世界で一番魅力的だ(自発的な選択・自己報酬の獲得)」と思わせる環境と条件を整えることです。
動物行動学の研究においても、罰を用いた訓練よりも、高い価値を持つ報酬を用いた正の強化トレーニングの方が、服従性や呼び戻しの成功率を有意に高めることが証明されています(Hiby et al., 2004, Animal Welfare)。
100%保証できない理由を理解する
どれほど完璧にトレーニングを積んだトップレベルの競技犬であっても、目の前を小動物が横切ったり、予期せぬ突発的な動きがあったりした場合、理性が吹き飛んで本能のスイッチが完全にオンになることがあります。現在の獣医学的・動物行動学的見地から、「いかなる状況下でも100%確実に捕食本能を抑制し、呼び戻せる」という科学的根拠は確認されていません。
だからこそ、「完全に安全が担保された閉鎖空間(二重扉や高いフェンスのあるドッグランなど)以外では、絶対にリードを外さない」という鉄則を遵守することが、愛犬の命を守る最後の砦となります。
2. ウィペットはなぜ逃げる?逃走事故が起きる3つの理由
ウィペットが呼び戻しに反応しなくなる最大の理由は「視覚刺激による本能の起動(プレイドライブ)」です。走る対象を見つけると脳内の報酬系(ドーパミン系)が活性化すると考えられており、強い刺激が認知心理学でいう「Attentional Capture(刺激による注意の強制的な奪取)」を引き起こすため、音声指示への反応が大きく低下します。
理由①:時速50km超でパニック走行する圧倒的な身体能力
ウィペットは、わずか数歩で時速50kmを超えるトップスピードに到達できる驚異的なバネを持っています。これを可能にしているのが、前足と後足が空中で交差して完全に体が宙に浮く「ダブルサスペンションギャロップ」という特殊な走法です。速筋繊維の割合が極めて高い筋肉と、極端に柔軟な脊椎が鞭のようにしなることで爆発的な推進力を生み出します。
一度何かに驚いてパニックになったり、獲物を追って走り出したりすると、数秒で飼い主の視界から消え去ります。この「自動車と同等のスピード」が、他の犬種と比べて逃走が致命的な交通事故に直結しやすい最大の要因です。
理由②:視覚的な刺激でスイッチが入る「追跡本能」
風で舞い上がったレジ袋、遠くを走る他の犬、茂みから飛び出した猫。これらを視覚で捉えた瞬間、以下の回路が脳内で瞬時に作動します。
| ステップ | 脳内・身体で起きていること |
| ① 視覚刺激 | 発達した網膜(ビジュアル・ストリーク)が「動く対象」を広角高解像度で捉える |
| ② 本能の起動 | 扁桃体が反応し、追跡のスイッチが強制的にオンになる |
| ③ 報酬系の活性化 | 追跡行動は中脳辺縁系の報酬系(ドーパミン系)と関連する行動と考えられており、「快楽(自己報酬)」として脳を満たす |
| ④ 追跡行動の開始 | 筋肉に大量の血液が集中し、トップスピードで駆け出す |
| ⑤ 注意の捕捉(Attentional Capture) | 強い視覚刺激によって注意処理が独占され、音声指示への反応が著しく低下する |
動物行動学において、犬の「捕食モーターパターン(Predatory Motor Sequence)」は「定位→注視→忍び寄り→追跡→捕捉噛み→殺傷噛み→解体→消費」という一連の行動プロセスとして定義されています(Coppinger & Coppinger, 2001; Bradshaw, 2011)。
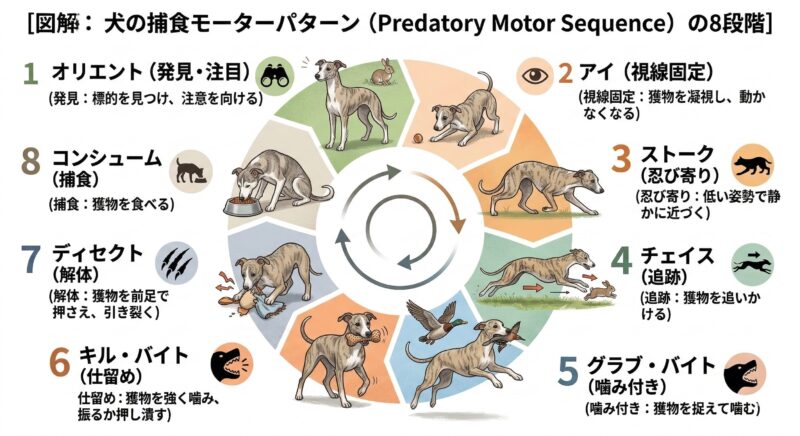
ウィペットは長年の選択交配により、「注視」から「追跡」にかけての欲求が遺伝的に極めて強くセットされています。追跡行動そのものが犬にとって強い内的報酬となると考えられており、これは報酬予測誤差モデルで知られるドーパミン系の活動と関連すると指摘されています(Schultz, 1998)。
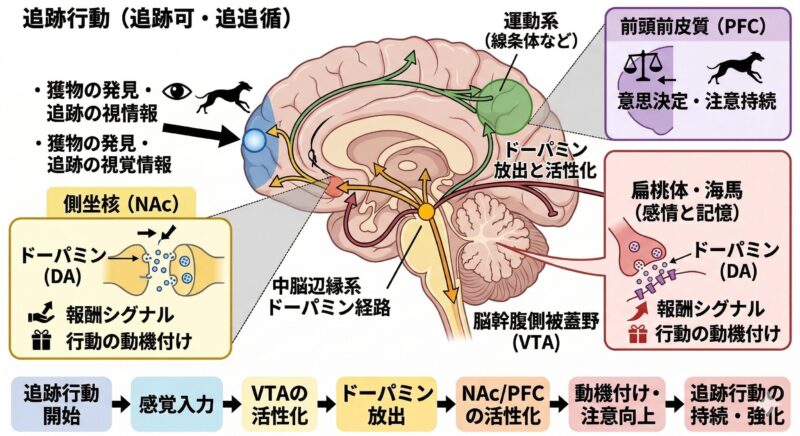
また、ドッグランで他の犬と遊んでいたはずが、相手の突発的な動きによってただの遊びが突然「本能的な狩り」に切り替わってしまう現象があります。ドッグトレーナーの間ではこれを**「捕食ドリフト(Predatory drift)」**と呼ぶことがあります。この状態に陥ると、認知心理学でいう「Attentional Capture(刺激による注意の強制的な奪取)」が起き、注意資源が視覚刺激に完全に独占されるため、聴覚(飼い主の声)に割くリソースが不足し、コマンドへの反応が著しく低下するのです。
【注意資源とは】
脳が同時に処理できる情報量・集中力の限界を示す心理学用語です。強い視覚刺激と追跡動機がこの注意資源を独占するため、犬は「わざと無視している」のではなく、「物理的に声が脳に届かない状態」にあります。
理由③:飼い主の「間違った対応」による逃避行動の誘発
犬が少し離れてしまった時、焦った飼い主が大きな声で怒鳴ったり、慌てて走って追いかけたりすることがあります。これが逃走をさらに加速させる引き金になります。
犬は飼い主の感情(焦り・怒り・恐怖)を、声のトーンや身振りから読み取る能力を持っています。犬が人間の感情状態を読み取る能力は**「情動感染(Emotional contagion)」**と関連すると考えられており(Custance & Mayer, 2012)、飼い主が血相を変えて追いかけてくる行動は、犬の目には「逃げなければ(逃避行動)」または「追いかけっこだ!(遊びの誘発)」と映り、パニックや興奮をさらに増幅させる要因となり得ます。
3. ウィペットの呼び戻しを成功させる「3つの原則」
呼び戻しの成功は「距離(短く)」「誘惑(少なく)」「成功体験(確実に)」の3つの原則で決まります。最初から難易度の高い場所(ドッグランなど)で練習すると、失敗を学習してしまうため逆効果です。
原則①:距離(Distance)のコントロール
トレーニングは必ず「絶対に手が届き、確実にコントロールできる短い距離」から始めます。まずは室内のわずか1メートルから「おいで」と呼び、確実に来たらご褒美をあげます。それができたら2メートル、違う部屋、次はお庭へ……と、何週間もかけて少しずつ距離を伸ばします。いきなり公園の端から数十メートル離れた状態で呼ぼうとするのは、準備運動なしでフルマラソンを走らせるようなものです。
原則②:誘惑(Distraction)の排除
「誘惑(ディストラクション)」とは、他の犬の匂い、鳥の声、車の音、落ち葉の動きなど、犬の注意を引くすべての環境刺激を指します。室内という「誘惑ゼロ」の環境で100%できるようになったら、次は人気の少ない早朝の公園へ移ります。周囲に犬が走り回り、様々な匂いが交錯するドッグランは「誘惑レベルが最大」の場所であり、トレーニングの最終段階まで挑んではいけません。
原則③:確実な成功体験の蓄積
「おいで」というコマンドを使う時は、必ず「犬がこちらに来る確証がある時」だけに絞ります。これは**「エラーレス・ラーニング(無誤謬学習)」**と呼ばれる、失敗を経験させずに正解だけを繰り返させる強力な学習手法です。
犬が匂い嗅ぎに夢中だったり、遠くの猫をロックオンしている時は、あえて呼びません。呼んで来なかった場合、犬は「『おいで』と言われても行かなくていい」という**失敗の学習(コマンドの形骸化)**を蓄積してしまうからです。確実に来るタイミングを見計らって呼び、必ず成功させることが最も確実な近道です。
 ローツェ
ローツェ「急がば回れ」という言葉通り、地味な室内での1メートルの練習こそが、外での劇的な成功につながります。
ゲームのレベル上げのように、少しずつ着実にステップアップしていきましょう。
4. 「おいで」を最強にする!報酬の階層化戦略と注意点
呼び戻しには、日常のフードとは異なる「最高価値の特別なご褒美」が不可欠です。環境の難易度に合わせてご褒美のレベルを上げる「階層化」が成功の鍵です。食物に対するモチベーションは、報酬の「目新しさ」や「肉類などの品質」によって有意に向上することが示されています(Riemer et al., 2018, Applied Animal Behaviour Science)。
報酬の価値を極限まで高める「階層化戦略」
| 報酬レベル | トリーツの種類 | 使用するシチュエーション | 期待される効果 |
| レベル1(低) | いつものドライフード | 室内での練習、日常のアイコンタクト | 毎日の小さな成功体験の積み重ね |
| レベル2(中) | 無添加の馬肉ジャーキーなど | 人気の少ない広場、ロングリードでの散歩中 | 外の軽い刺激の中でも戻る習慣を定着 |
| レベル3(高) | ボイルした鶏むね肉 | 一般的なドッグラン、他の犬がいる環境 | 強い刺激を断ち切る動物性タンパクの誘引力 |
| レベル4(最高) | 新鮮な生肉・ヤギミルク ※衛生管理必須(詳細は下記) | ルアーコーシング競技後など、極限の興奮状態 | 強い追跡動機を上回り意識を飼い主へ向けさせる究極の報酬(ジャックポット) |
5. 実体験:ローツェがドッグランで捕まらなくなった日と「キャッチ&リリース法」
ドッグランで捕まらなくなる理由は、犬が「呼ばれる=楽しい遊びの強制終了(帰宅)」と学習してしまったからです。解決策は、呼び戻してご褒美をあげたらすぐにまた遊ばせる「キャッチ&リリース」の反復です。
失敗体験:ドッグランが「罰」に変わった瞬間
広島で生まれ、我が家に迎えたウィペット姉妹の姉、ローツェ(2024年10月生)がまだ幼かった頃の話です。休日にドッグランへ連れて行き、楽しく走り回らせた後、帰る時間になると「ローツェ、おいで!」と呼んでリードをつけ、帰宅していました。これを数週間繰り返したある日、明確な異変が起きました。「おいで」と呼ぶと、私の2メートル手前でピタッと立ち止まり、決して手を伸ばせる距離まで近づいてこなくなったのです。一歩近づくと、サッと後ろへ一歩下がる。完全に警戒されています。
理由は明確でした。ローツェは極めて賢いがゆえに、古典的条件づけによって**「おいでと呼ばれて飼い主のところへ行く=リードをつけられてドッグランが強制終了する」**という図式を完璧に学習してしまったのです。私にとっての呼び戻しが、犬にとっては「楽しい時間の終わりを告げる罰」になっていた——あの瞬間のハッとした感覚と絶望感は今でも忘れられません。
解決策:遊びを途切れさせない「キャッチ&リリース法」
そこで私は、トレーニングの概念を180度転換しました。ドッグランに入り、ローツェが楽しく遊び始めたら、数分おきに「おいで!」と呼びます。戻ってきたら、最高価値のご褒美(ボイルしたお肉など)を連続で口に入れ、うんと褒め称えます。そして**リードは絶対につけず、すぐに「よし、また遊んでおいで!」と笑顔で送り出した(リリースした)のです。これは行動学における「プレマックの原理(犬が今最もやりたい行動自体をご褒美として使う)」**の応用です。
これを1回のドッグランの中で何度も繰り返した結果、ローツェの脳内は「呼ばれて戻ると、とびきり美味しいおやつがもらえて、しかもまたすぐに遊べる!」と完全に上書きされました。
ローツェ「呼ぶのは帰る時だけ」というのは人間側の都合です。
「戻る=もっと良いことがある」という約束をコツコツ積み上げていくことが、どんな犬種においても信頼の土台になります。
6. サイトハウンド競技者が実践する「リコール回収テクニック」
競技中の極限の興奮状態では、犬に名前を呼んでも声は届きません。安全に回収するためには「無言での待機」「視線の物理的な遮断」「ハンドターゲットと最高報酬の組み合わせ」というルーティンが不可欠です。
ルアーコーシング等で起きる生理的反応の理解
ウィペットが最も輝くスポーツの一つに、疑似餌を追う「ルアーコーシング」があります。秋田にある1周262mのパウダーサンドのオーバルコースのような、脚への負担が少なく最高のパフォーマンスを発揮できる環境でルアーが動いた瞬間、ウィペットの目は完全にロックオンされ、血中のアドレナリンとコルチゾールは一気にピークに達します。ゴール直後の彼らは「狩猟モード」のただ中にあり、Attentional Captureによって注意資源が視覚刺激へ集中しているため、遠くから「おいで!」と叫んでも音声指示への反応は著しく低下しています。
スポーツドッグの安全な回収ルーティン
- 無言のポジショニング(名前を呼ばない)
ゴール地点で犬がルアーをくわえた瞬間、絶対に名前を叫びません。無駄な声かけはコマンドの価値を下げるだけです。ハンドラーは無言で犬の動線を予測し、姿勢を低くして待機します。 - 視線の物理的な遮断
ルアーに釘付けになっている犬の視線を切るため、ハンドラーの体または手(ハンドターゲット)を犬の視界の前に物理的に割り込ませます。ここで初めて、犬の注意資源が「狩り」から「目の前の飼い主」へと再配分されます。 - ハンドターゲットと最高報酬の提示
事前にトレーニングしておいた「手のひらに鼻先を当てる」動作(ハンドターゲット)をさせ、成功した瞬間に飼い主が最大限に褒め称え、その隙にスリップカラーやリードを素早く確保します。
▼ ローツェのルアーコーシングの全記録はこちら ▼

▼ ローツェもここから育ちました。一緒に楽しく走りませんか?▼

▼ 大阪から秋田への挑戦は、ここから始まります!▼

▼ 大阪から秋田へ。Supersonic Racing Parkという“聖地”が成長を加速させる理由 ▼

▼ 愛犬と目指す、日本唯一の砂の聖地。14時間の長距離遠征を成功させる鉄則 ▼

▼ 初めての挑戦もこれで安心! 【全国版】ルアーコーシング体験会・練習会スケジュールを確認する ▼

【競技者向けコラム】リコールを裏で支える「スタート4時間前の食事管理」
※以下は競技参加者向けの安全管理に関する実務情報です。一般の飼い主の方は参考情報としてご覧ください。
競技現場における安全管理とリコール成功率を高めるための重要な実務ルールが、**「スタートの4時間前までに固形物の給与を完全に終える」**ことです。時速50kmでの急発進・急旋回を行う際、胃の中に固形物が残っていると「胃拡張・胃捻転(GDV)」という致死率の高いリスクを引き起こすため、消化管を空にしておく必要があります。加えて、この「適度な飢餓状態」が競技直後のご褒美への執着心を極限まで高め、強い本能的動機付けを上回るリコールの原動力として機能します。
▼ 胃捻転を防ぎ、最高のタイムを出す。4時間前の0.5%給餌とアミノペッツ活用の全技術。 ▼

7. 呼び戻しトレーニングで絶対にやってはいけない5つのミスと、緊急時の対応
どんなにトレーニングを頑張っても、飼い主が無意識にやってしまうことで成果がすべて台無しになります。
呼び戻しトレーニングで絶対にやってはいけない5つのミス
① 呼び戻して叱る(最も確実に関係を壊す行為)
なかなか戻ってこなかった犬がようやく帰ってきた時、「どこ行ってたの!ダメでしょ!」と怒っていませんか? 犬は「戻ってきたこと」に対して叱られたと勘違いし、「飼い主のところに行くと嫌なことがある」と学習します。どんなに腹が立っても、戻ってきた時は必ず笑顔で褒めちぎるのが絶対の鉄則です。

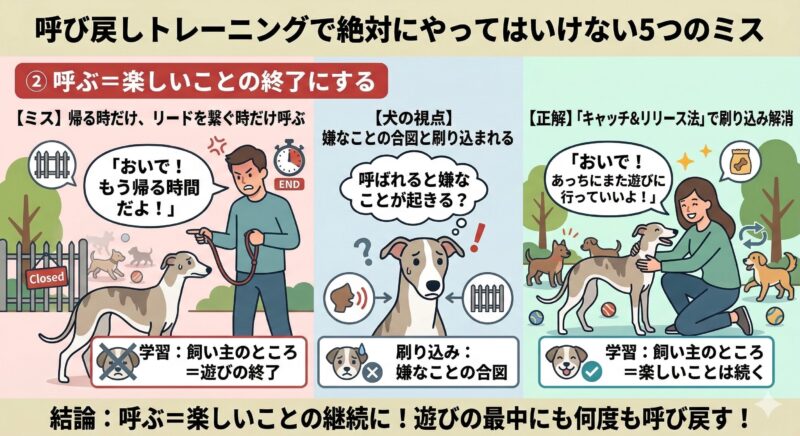
② 呼ぶ=楽しいことの終了にする
帰る時だけ、あるいはリードを繋ぐ時だけ呼ぶのはNGです。呼び戻しが「嫌なことの合図」になってしまいます。前章の「キャッチ&リリース法」でこの刷り込みを解消してください。
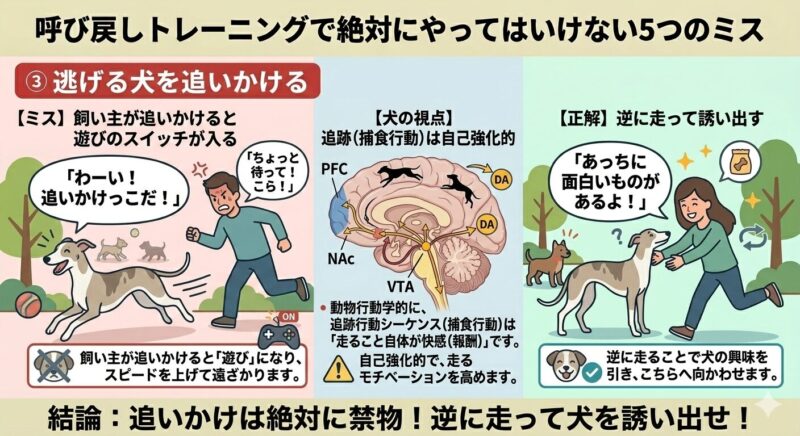
③ 逃げる犬を追いかける
飼い主が慌てて追いかけると「わーい!追いかけっこだ!」と遊びのスイッチが入り、さらにスピードを上げて遠ざかります。追跡という捕食行動シーケンスが自己強化的であることは動物行動学的に広くコンセンサスが得られており、追いかけは絶対に禁物です。
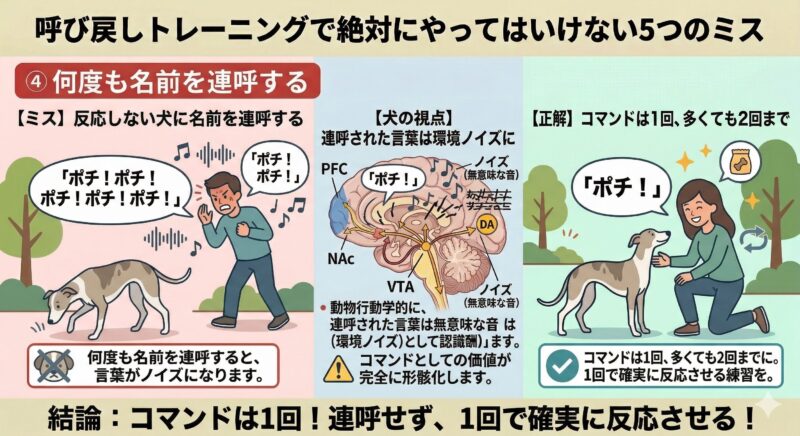
④ 何度も名前を連呼する
反応しない時に名前を連呼すると、犬にとってその言葉は単なる「環境ノイズ」に成り下がり、コマンドとしての価値が完全に形骸化します。コマンドは1回、多くても2回までにとどめましょう。
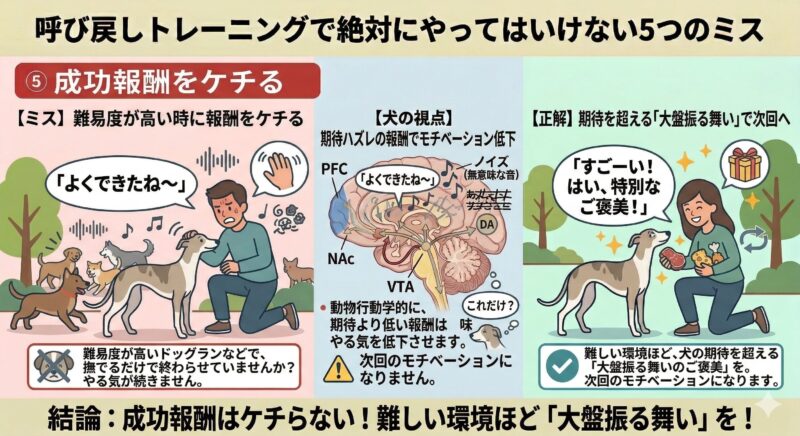
⑤ 成功報酬をケチる
ドッグランなどの難しい環境でせっかく戻ってきてくれたのに、「よくできたね〜」と撫でるだけで終わらせていませんか? 難易度が高い時ほど、犬の期待を超える「大盤振る舞いのご褒美」が次回のモチベーションを担保します。
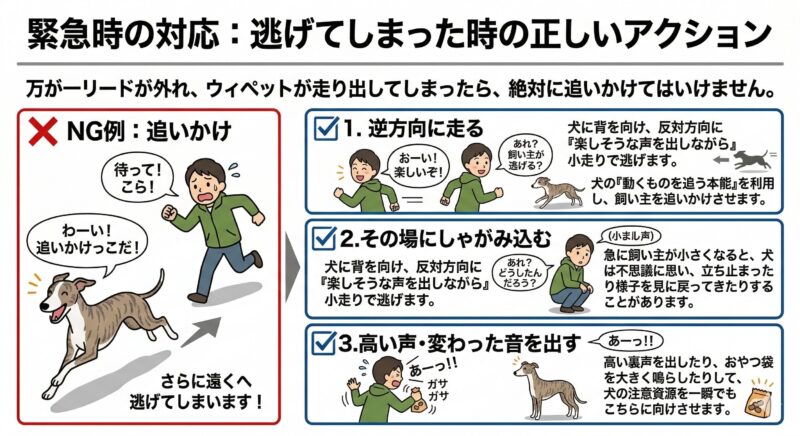
緊急時の対応:逃げてしまった時の正しいアクション
万が一リードが外れ、ウィペットが走り出してしまったら、絶対に追いかけてはいけません。
- 逆方向に走る
犬に背を向け、反対方向に「楽しそうな声を出しながら」小走りで逃げます。犬の「動くものを追う本能」を逆手に取り、飼い主を追いかけさせる心理的誘導です。 - その場にしゃがみ込む
急に飼い主が小さくなると、犬は「あれ?どうしたんだろう?」と不思議に思い、立ち止まったり様子を見に戻ってきたりすることがあります。 - 高い声・変わった音を出す
「あーっ!!」と高い裏声を出したり、おやつ袋をガサガサと大きく鳴らしたりして、犬の注意資源を一瞬でもこちらに向けさせます。
 ローツェ
ローツェ緊急時に冷静でいるのは本当に難しいことです。
だからこそ「追いかけたら負け。逃げるフリをして気を引く」というルールを、普段から頭の中でシミュレーションしておくことが、いざという時の愛犬の命を守ります。
8. 成功率を高める日常トレーニング
呼び戻しの土台は競技場でもドッグランでもなく、家の中に存在します。
室内での「かくれんぼ」から始める関係構築
犬が別の部屋にいる隙に、押入れやカーテンの後ろにこっそり隠れてみましょう。犬は「飼い主がいない!」と気づいた瞬間、本能的に探し始めます。見つけてもらった時に思い切り褒めてご褒美を渡すことで、「飼い主を探して見つける=最高に良いことがある」という回路が強化されます。「飼い主への追従(フォロイング)」という本能を育てる、最も手軽で効果的な練習です。
ロングリードを活用した安全なトレーニング環境の作り方
ロングリード(10〜15m)は、呼び戻しトレーニングにおける最重要ツールです。犬にフリーに動き回る感覚を与えながら、飼い主は常に安全をコントロールできます。コマンドに反応しない場合でもリードを手繰ることで「失敗の学習」を防ぎ、原則③「確実な成功体験の蓄積」を屋外でも実践できます。
ウィペットの呼び戻しに関するよくある質問(FAQ)
- サイトハウンドは呼び戻しできないって本当ですか?
-
完全に不可能ではありません。
犬種特有の追跡本能(プレイドライブ)が極めて強いため、他の犬種と比べて難易度が高いのは事実です。しかし、本能のメカニズムを理解し、適切な報酬を用いたトレーニングと環境管理を徹底することで、成功率は大きく向上します。 - ウィペットがドッグランで捕まえられないのですが?
-
「呼ばれる=帰らされる(楽しいことの終了)」と学習している可能性が高いです。
遊びの最中に何度も呼び戻し、とびきりのご褒美をあげたら、またすぐに遊ばせる「キャッチ&リリース法」を実践してください。 - トレーニング用のロングリードは何mがおすすめですか?
-
10m〜15mのものが一般的で扱いやすくおすすめです。
長すぎると絡まりやすく、短すぎると走る距離が確保できないため、このレンジが日々のトレーニングに最適です。 - ご褒美として生肉を与えても大丈夫ですか?
-
非常に魅力的な報酬ですが、徹底した衛生管理が必須です。
馬肉などの新鮮な生肉は究極のご褒美になり得ますが、サルモネラ菌やカンピロバクターなどの食中毒リスクが伴います。使用する場合は人間用の生食用と同等の鮮度管理を行ってください。免疫力の低い時期やシニア犬には控え、まずは加熱済みの肉類(ボイルした鶏肉など)を使用するか、事前にかかりつけの獣医師にご相談ください。
ウィペットの呼び戻し:本能を理解し、揺るぎない「信頼の絆」を築くために

ウィペットの呼び戻し(リコール)は、単なる「しつけ」の枠を超えた、愛犬の命を守るための究極のスキルです。彼らが時速50kmという圧倒的なスピードで爆走し、飼い主の声を無視してしまうのは、決してワガママだからではありません。それは、数百年かけて研ぎ澄まされてきたサイトハウンドとしての鋭い本能(プレイドライブ)と、特定の刺激に対して注意が独占される脳の仕組みがあるからです。
この記事で解説した、距離・誘惑・成功体験という「3つの原則」、そして状況に合わせてご褒美の価値を使い分ける「報酬の階層化戦略」を正しく実践すれば、本能を力技で抑え込むのではなく、賢く「味方」につけることは十分に可能です。特にドッグランでの「キャッチ&リリース」の実践は、呼び戻しへのネガティブな学習を払拭し、「戻ればもっと良いことが起きる」という期待感を愛犬の脳に深く刻み込みます。
また、ルアーコーシング競技の現場で培われた専門的な回収ルーティンや、安全管理とモチベーション維持を両立させる「4時間前の食事ルール」といった知見も、日常のあらゆる場面であなたを助ける強力な武器になるでしょう。
トレーニングに「100%の絶対」は存在しません。だからこそ、科学的な根拠に基づいた正しい手法を選び、焦らず一歩ずつ信頼関係を積み重ねていくことが大切です。不安が安心に変わり、愛犬が笑顔で一直線にあなたのもとへ駆け寄るその瞬間、そこには世界に一つだけの特別な絆が生まれています。
あなたの愛犬が健康に暮らし、あなたと一緒に最高の思い出ができることを願っています。
ローツェ最後まで読んでいただきありがとうございました。
もしよかったら下のボタンからインスタにも遊びに来てね!
参考文献・科学的根拠
本記事は推測や一般論を排除し、以下の研究および行動学的・神経科学的コンセンサスを背景に執筆しています。
- Coppinger, R., & Coppinger, L. (2001). Dogs: A Startling New Understanding of Canine Origin, Behavior & Evolution. Scribner. (捕食モーターパターン[Predatory Motor Sequence]の理論的枠組み)
- Bradshaw, J. (2011). Dog Sense: How the New Science of Dog Behavior Can Make You A Better Friend to Your Pet. Basic Books. (犬の行動学および捕食シーケンスに関する補助的見解)
- Custance, D., & Mayer, J. (2012). Empathic-like responding by domestic dogs (Canis familiaris) to distress in humans: an exploratory study. Animal Cognition, 15(5), 851–859. (犬が人間の感情に同調する情動感染[Emotional contagion]の根拠)
- Schultz, W. (1998). Predictive reward signal of dopamine neurons. Journal of Neurophysiology, 80(1), 1–27. (中脳辺縁系のドーパミン報酬系に関する基本論文。報酬予測研究の神経科学的根拠)
- McGreevy, P. D., Grassi, T. D., & Harman, A. M. (2004). A strong correlation exists between the distribution of retinal ganglion cells and nose length in the dog. Brain, Behavior and Evolution, 63(1), 60–66. (長頭種の網膜におけるVisual streakの発達と広視野特性の解剖学的根拠)
- Hiby, E. F., Rooney, N. J., & Bradshaw, J. W. S. (2004). Dog training methods: their use, effectiveness and interaction with behaviour and welfare. Animal Welfare, 13(1), 63–69. (報酬ベース訓練が罰より服従性・呼び戻し成功率を有意に高める根拠)
- Riemer, S., Ellis, S. L., Thompson, H., & Burman, O. H. (2018). Reinforcer effectiveness in dogs—The influence of quantity and quality. Applied Animal Behaviour Science, 206, 87–93. (食材の価値や新奇性が犬の食物モチベーションに影響を与える根拠)
- Rooney, N. J., & Cowan, S. (2011). Training methods and owner–dog interactions: Links with dog behaviour and learning ability. Applied Animal Behaviour Science, 132(3–4), 169–177. (トレーニング方法と飼い主・犬間の相互作用が犬の行動と学習能力に与える影響)
- 日本獣医師会(公式見解).「犬猫における生肉給与の健康リスクと人獣共通感染症に関する注意喚起」. (生肉給与に関する衛生上のリスクと獣医学的コンセンサスの根拠)
